最近用到了nutch,目的是针对指定的一些网站抓取其内容,然后做分析用。
nutch 笔记是我使用nutch过程一系列总结,写下自己的学习经过和大家一起分享,也希望能得到大家的指点

好了,废话少说,言归正传,第一篇:Quick Start,我们的目标是快速的能跑起来,能检索出我们想要的结果。
首先要明白nutch是什么?
nutch是一个基于lucene的开源搜索引擎,它包括了所有你想要的东西,是一个完整的解决方案 。
一:安装JDK
如果你已经安装了JDK,并且已经设置了JAVA_HOME,那么跳过这一步
安装jdk
sudo apt-get install sun-java5-jdk
或者从sun公司网站下载bin文件执行安装
设置了JAVA_HOME
sudo vi ~/.bashrc
在最后面增加
export JAVA_HOME=/usr/lib/jvm/java-1.5.0-sun
export PATH=$PATH:$JAVA_HOME/bin
二:下载nutch的最新版本nutch0.8.1
wget http://apache.justdn.org/lucene/nutch/nutch-0.8.1.tar.gz
释放下来即可
tar zxvf nutch-0.8.1.tar.gz
三:抓取页面
增加url
cd nutch-0.8.1
mkdir urls
echo http://www.xici.net>>urls/xici
编辑conf/crawl-urlfilter.txt,修改MY.DOMAIN.NAME为
+^http://([a-z0-9]*.)*xici.net/
修改conf/nutch-site.xml,增加http.agent.name值
<property>
<name>http.agent.name</name>
<value>test/unique</value>
</property>
执行bin/nutch crawl开始抓取页面
sudo bin/nutch crawl urls -dir crawl -depth 5 -topN 50&
这个过程需要等待一些时间
三:检索
安装tomcat,我们使用apache网站上的包
cd ..
wget http://mirror.vmmatrix.net/apache/tomcat/tomcat-5/v5.5.20/bin/apache-tomcat-5.5.20.tar.gz
tar zxvf apache-tomcat-5.5.20.tar.gz
将nutch自带的war文件拷贝到webapps下面
rm -rf apache-tomcat-5.5.20/webapps/ROOT*
cp nutch-0.8.1/nutch*.war apache-tomcat-5.5.20/webapps/ROOT.war
运行tomcat,如果不设定nutch-site.xml的searcher.dir的值,则需要在crawl目录下面执行
sudo ${TOMCAT的目录}/bin/startup.sh
我们也可以设定nutch-site.xml的searcher.dir的值
sudo vi ${TOMCAT的目录}/webapps/ROOT/WEB-INF/classes/nutch-site.xml
增加
<property>
<name>searcher.dir</name>
<value>/home/martin/doc/nutch-0.8.1/crawl</value>
</property>
四:中文乱码
修改tomcat的server.xml,在Connector的tag最后增加
URIEncoding="UTF-8"
五:截图
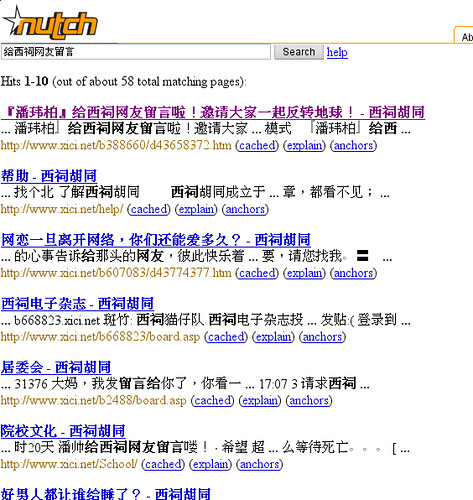
-----------------------
nutch site:http://lucene.apache.org/nutch
nutch wiki:http://wiki.apache.org/nutch/
下一篇笔记:Nutch 笔记(二):Craw more urls and Recrawl:
http://martin.iteye.com/blog/27193
分享到:





相关推荐
NULL 博文链接:https://chenhua-1984.iteye.com/blog/380779
nutch入门经典翻译1:Introduction to Nutch, Part 1: Crawling
## Nutch2.3.1新闻分类爬虫内容项目介绍本项目基于https://github.com/xautlx/nutch-ajax.git的nutch-ajax项目功能很强大,本项目在此基础上,对nutch-ajax项目做了一些精简和优化,对Nutch版本进行升级,♡Mybatis...
坚果桂Apache Nutch Web UI 源代码首先从Apache Nutch 2.3版签出。
Nutch AJAX page Fetch, Parse, Index Plugin项目简介基于Apache Nutch 2.3和Htmlunit, Selenium WebDriver等组件扩展,实现对于AJAX加载类型页面的完整页面内容抓取,以及特定数据项的解析和索引。According to the...
BCube Crawler 是 Apache Nutch 项目(1.9 版)的一个分支,经过调整后可以在 Amazon 的 ElasticMapReduce 上运行,并针对 Web 服务和数据发现进行了优化。 动机 建立一个健康的 Hadoop 集群并不总是一件容易的事,...
初学NUTCHLUCENCENUTCH可以看
Nutch 1.3 学习笔记,讲的比较清楚的文档
Nutch 解析器parse部分代码笔记
nutch 爬虫数据nutch 爬虫数据nutch 爬虫数据nutch 爬虫数据nutch 爬虫数据nutch 爬虫数据nutch 爬虫数据nutch 爬虫数据nutch 爬虫数据
( Nutch,第1部分:爬行(译文) ( Nutch,第1部分:爬行(译文)
一、org.apache.nutch.crawl.Injector: 1,注入url.txt 2,url标准化 3,拦截url,进行正则校验(regex-urlfilter.txt) 4,对符URL标准的url进行map对构造, CrawlDatum>,在构造过程中给CrawlDatum初始化得分...
本文是我学习Nutch的笔记,包括安装、配置、修改分词和关键词的代码;还有Luke和Lius的简单配置;
Nutch,第2部分:搜索(译文) Nutch,第2部分:搜索(译文)
NULL 博文链接:https://qidaoxp.iteye.com/blog/1072832
Nutch2.3.1 环境搭建 Nutch2.3.1 环境搭建 Nutch2.3.1 环境搭建 亲测可用,我自己安装和搭建过程的记录文档
Nutch:从搜索引擎到网络爬虫。中文。
Nutch 是一个开源的、Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。 目 录 1. nutch简介...1 1.1什么是nutch..1 1.2研究nutch的原因...1 1.3 nutch的目标..1 1.4 nutch VS lucene.....2 2....
我们需要去抓取网页数据的时候我们就用nutch来爬取,我们对它进行二次开发使其更加符合我们的需求